并发编程中的锁、条件变量和信号量
在并发编程中,经常会涉及到锁、条件变量和信号量。本文从并发开始,探究为什么需要它们,它们的概念,实现原理以及应用。
并发简介
并发是指多个事情,在同一时间段内同时发生了。和并发经常一起被提到的是并行。并行是指多个事情,在同一时间点上同时发生了。
本质上来说,并发是为了程序运行的速度更快。在实际开发中,我们可能会遇到比较耗时的操作,例如I/O操作。在整个程序运行过程中,如果某个阶段因为一直等待I/O而阻塞整个程序,就会降低程序的运行速度。为了提升程序的运行速度,我们可以新开一个线程进行I/O操作,操作完成后通知主线程,从而提升程序的运行速度。
并发带来的问题
并发虽然提升了程序的运行速度,但是不恰当的使用并发可能会带来一系列问题,原因在于并发是无法确定各线程执行的先后顺序的。
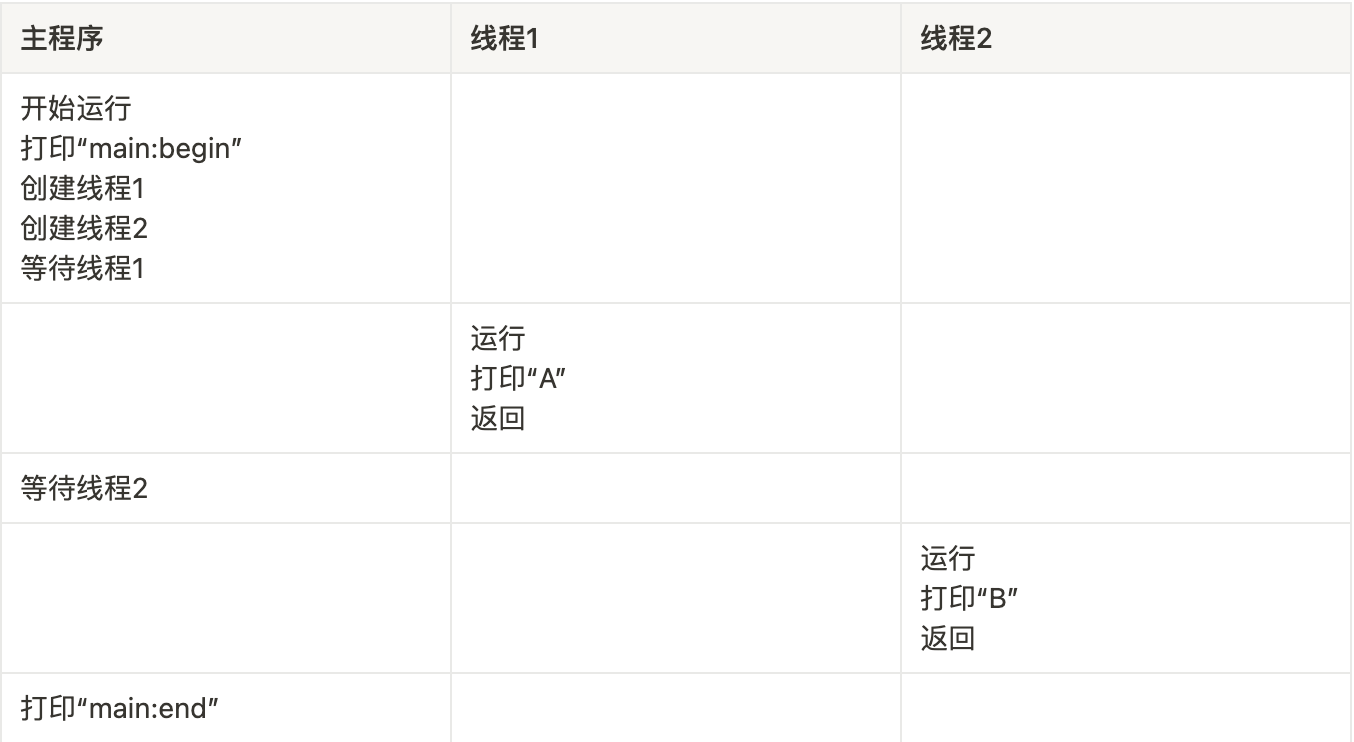
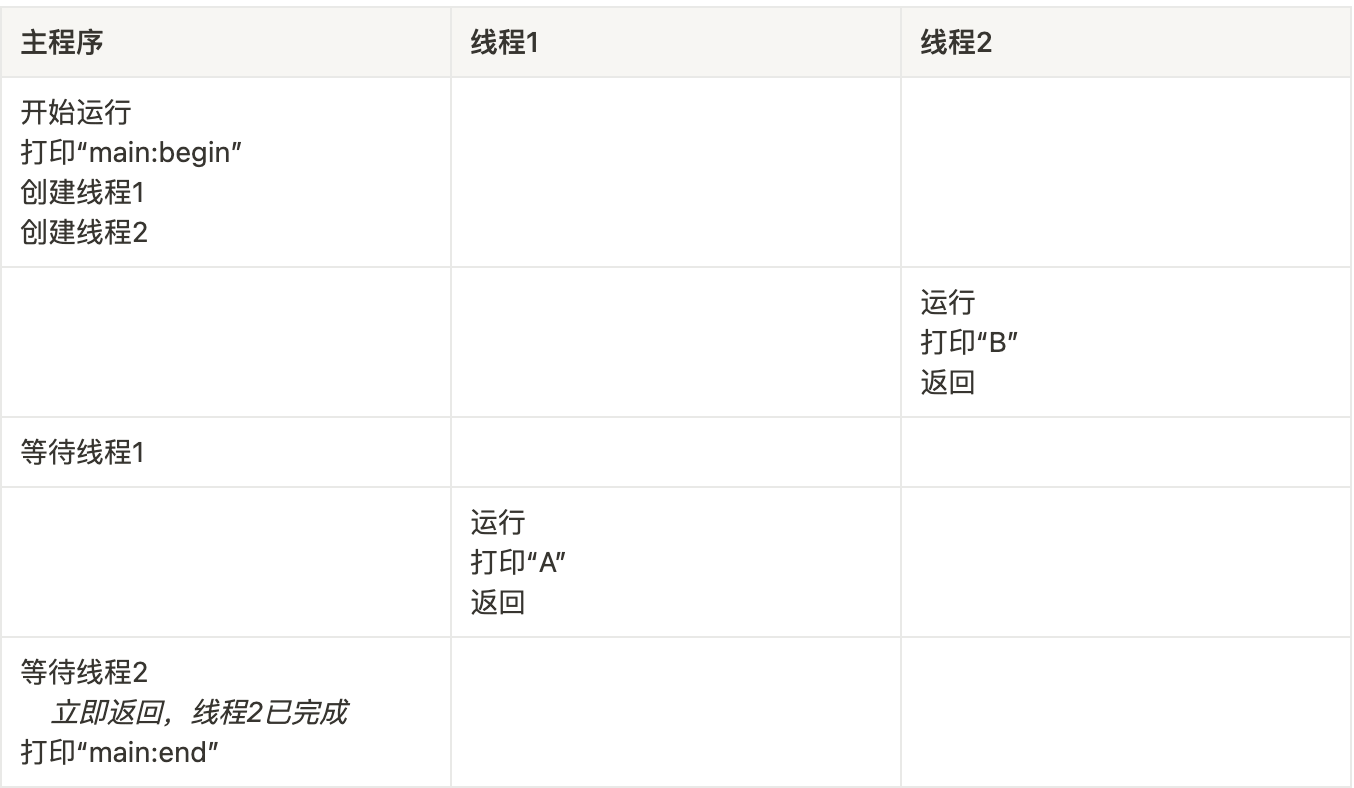
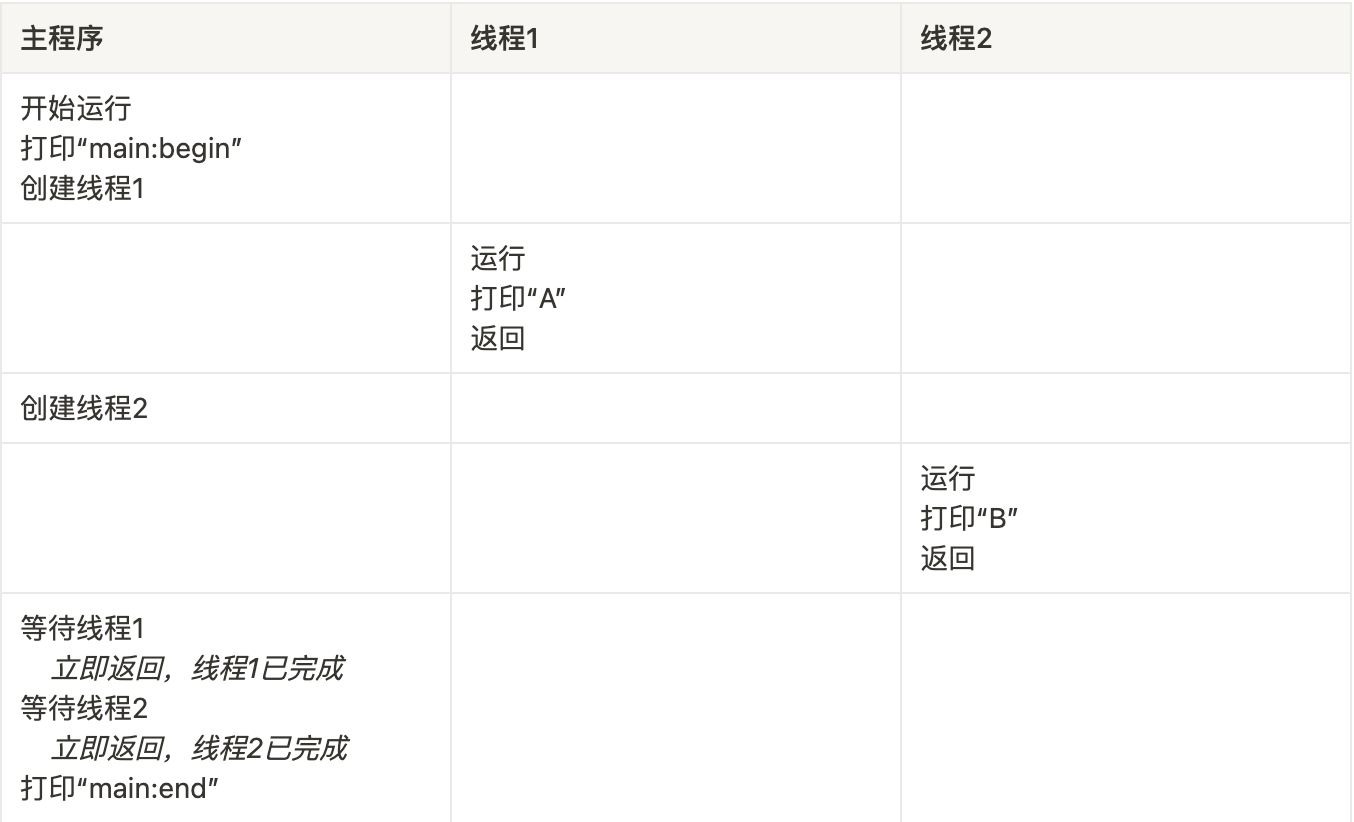
假设我们想运行一个程序,它创建两个线程,每个线程都做了一些独立的工作(本例中打印“A”或“B”),代码如下:
|
|
Tips
pthread_create:创建线程(实际上就是确定调用该线程函数的入口点),在线程创建以后,就开始运行相关的线程函数;pthread_join:主线程等待子线程的终止。
以上代码可能的运行顺序如下:
还有更大的问题在于当多个线程操作共享数据时,会带来不可预期的结果,看如下代码:
|
|
该代码理论上会输出:
|
|
但是实际在多次运行过程中输出结果如下:
|
|
我们预期的计算结果是200000,但实际代码在执行过程中,运行结果是不确定的。
并发带来不可控的调度
上面代码运行结果不确,原因在于并发带来了不可控的调度。
我们知道每个线程有自己的一组用于计算的寄存器。所以,当两个线程运行在同一个处理器上时,从线程 1 切换到线程 2 必定发生上下文切换,线程切换需要线程控制块(Thread Control Block,TCB)来保存每个线程的状态。
上面代码中,语句 counter += 1 在 x86 中的汇编指令如下:
|
|
假设变量counter在地址0x8409c2d。上面三条指令的具体含义如下:
- 首先
mov指令从内存地址0x8409c2d取出counter,放入 eax 寄存器; - 给 eax 寄存器的值加 1 (0x1);
- 将 eax 的值存回内存中相同的地址。
在上面代码的执行过程中,可能出现这样的情况:
- 线程 1 进入代码区,并且将计数器 +1,它将
counter的值(假设此时等于 20)加载到它的寄存器 eax 中,因此线程 1 的 eax = 20,然后它向寄存器加 1,eax = 21; - 此时,发生时钟中断,操作系统将当前正在运行的线程(它的程序计数器、寄存器,包括 eax 等)的状态保存到线程的 TCB;
- 线程 2 开始运行,进入同一段代码。它也执行了第一条指令,获取计数器的值放入其 eax 中(运行时每个线程有自己的专用寄存器。上下切换代码将寄存器虚拟化,保存并恢复它们的值)。此时
counter的值仍然为 20。接下来线程 2 运行后面的两条指令,将 eax 中保存的值 +1,然后将 eax 中的内容保存到counter中,此时counter的值为 21; - 时钟中断再次发生,上下文切换,线程 1 恢复运行。它在之前已经执行过
mov和add指令,所以此时它执行最后一条mov指令(此时 eax = 21),将值保存到内存,counter再次被设置成 21。
原子方式执行
从以上可以看出,由于时钟终端,导致了counter虽然被加了两次,但表现出来的结果是被加了一次。我们期望拥有一个不可被中断的指令,从而消除不合时宜的中断,得到正确的运行结果,即期望以原子方式执行。
所谓原子方式即要么运行完成,要么没有运行,不会存在中间态。上面代码中我们期望以原子方式执行 3 个指令:
|
|
要想做到这一点,就需要硬件提供一些有用的指令,在这些指令上构建一个通用的集合,即所谓的同步原语。通过使用同步原语,加上操作系统的一些帮助,就可以构建多线程代码,以同步和受控的方式访问临界区,从而可靠的产生结果。
并发术语:临界区、竞态条件、不确定性、互斥执行
- 临界区(critical section):访问共享资源的一段代码,资源通常是一个变量或数据结构。
- 竞态条件(race condition):出现在多个执行线程大致同时进入临界区时,它们都试图更新共享的数据结构,这导致了不确定的运行结果。
- 不确定性(indetermination):程序由一个或多个竞态条件组成,程序的输出因运行而异,具体取决于哪些线程在何时运行。这导致结果不是确定的。
- 为了避免以上问题,线程应该采用某种互斥(mutual exclusion)原语。这样做可以保证只有一个线程进入临界区,从而避免出现竞态,保证程序输出确定的结果。
并发问题的解决
通过前面对并发的介绍以及并发带来的问题,我们知道如果临界区能够像单条原子指令一样执行,那么就可以保证程序运行正确。我们通过引入锁来保证临界区代码的正确执行。
锁
什么是锁
锁本质上是一个变量,因此我们需要声明一个某种类型的锁变量才能使用。这个锁变量保存了锁在某一时刻的状态。它要么是可用的(available,或 unlocked,或 free),表示没有线程持有锁,要么是被占用(acquired,或 locked,或 held),表示一个线程持有锁,正处于临界区。锁变量也可以保存其他信息,例如持有锁的线程,请求锁的线程队列等,但这些信息会被隐藏起来,锁的使用者不会发现。
锁的持有者一旦调用 unlock(),锁就变成可用了。如果没有其他等待线程(即没有其他线程调用过lock()并卡在那里),锁的状态就变成可用了。如果有等待线程(卡在lock()里),其中一个会注意到锁状态的变化,获取该锁,进入临界区。
锁的使用
POSIX(Portable Operating System Interface of UNIX,可移植操作系统接口)库将锁称为互斥量(mutex),它被用来提供线程之间的互斥,即当一个线程在临界区,它能够阻止其他线程进入直到该线程离开临界区。具体使用方式如下:
|
|
在 Go 中由 sync 包提供互斥锁,具体使用方式如下:
|
|
锁的实现
前面我们理解了锁的本质以及使用,那么如何实现一个锁呢?锁的实现需要硬件和操作系统的帮助。实现锁的硬件指令有控制中断指令、测试并设置指令、比较并交换指令、链接的加载和条件式存储指令、获取并增加指令。
控制中断
实现一个锁,首先能想到的就是控制中断,即在临界区关闭中断。代码如下:
|
|
假设我们运行在一个单处理器系统上,通过进入临界区之前关闭中断,就可以保证临界区的代码不会被中断,从而原子地执行。运行结束后再打开中断。
但这样的锁实现存在诸多问题:
- 需要信任调用线程:这种方法要求所有调用线能够执行特权操作(开关中断),即信任调用线程不会滥用这种机制;
- 不支持多处理器:如果多个线程运行在不同的处理器上,每个线程都试图进入同一个临界区,则关闭中断是没有用的。线程可以运行在其他处理上从而进入临界区;
- 效率较低:和其他指令相比,现代处理器对于打开和关闭中断的代码执行得较慢。
测试并设置(TSL)
由于关闭中断的方法存在以上问题,所以系统设计者开始让硬件支持锁。其中最简单的是测试并设置指令(test-and-set-lock instruction),又叫原子交换(atomic exchange)。测试并设置指令的逻辑如下:
|
|
以上代码是原子执行的。通过测试并设置指令,我们可以实现一个简单的自旋锁,具体代码如下:
|
|
其中测试和设置的原子执行保证了只有一个线程能够获取锁,这就实现了一个有效的互斥原语。
比较并交换(CAS)
比较并交换指令是系统提供的另一个硬件原语,具体逻辑如下:
|
|
利用CAS指令,就可以实现一个锁,类似于测试并设置,只需要将lock函数替换为:
|
|
链接的加载和条件式存储(LL/SC)
链接的加载和条件式存储 load-linked/store-conditional(LL/SC),又称 load-reserved/store-conditional (LR/SC),是一对用于并发同步访问内存的指令。这些指令的逻辑如下:
|
|
链接的加载指令和普通的加载指令类似,都是从内存中取出值然后存入一个寄存器。关键的区别在于条件存储指令(store-conditional),只有上一次加载的地址在期间没有更新时,条件存储指令才会在该内存位置保存新值。
利用链接的加载和条件式存储指令实现一个自旋锁的代码如下:
|
|
以上代码中,条件式存储发生失败的情况如下:
- 线程 A 调用
lock(),执行链接的加载指令,返回 0; - 在执行条件式存储之前,发生了中断;
- 线程 B 进入
lock代码,也执行了链式的加载指令,也返回了 0; - 线程 A 和 B 都执行了链式的加载指令,将要执行条件存储。但只有一个线程能够更新标志为1,从而成功获取锁;第二个执行条件存储的线程会失败,需要重新尝试获取锁。
获取并增加(FAA)
获取并增加(fetch-and-add)指令是最后一个硬件原语,它能原子地返回特定地址的旧值,并让该值自增一。该指令的逻辑如下:
|
|
利用 FAA 实现lock 和 unlock:
|
|
FAA 使用ticket和turn两个变量来构建锁,如果线程期望获取锁,首先对一个ticket值执行一个原子的获取并增加指令。得出的值(turn_data)作为该线程的 turn 值,当某个线程的 turn_data == turn 时,该线程进入临界区。
unlock用于增加turn值,从而使下一个等待线程进入临界区。
Go 中锁的实现
基于以上,我们看下 Go 中锁是如何实现的。Go 锁的实现在go/mutex.go at master · golang/go (github.com)中,lock和unlock的逻辑如下:
|
|
可以看到 Go 中使用比较并交换指令(atomic.CompareAndSwapInt32)实现lock和unlock函数。其中atomic.CompareAndSwapInt32的具体逻辑如下:
|
|
关于 Go 中锁的实现就介绍这么多,更详细的源码分析可以查看文章:Go源码解析之mutex。
条件变量(Condition)
上面介绍了锁的概念以及如何通过硬件和操作系统来实现锁,但锁并不是并发程序所需的唯一原语。很多时候线程需要在检查某一条件满足后,才继续运行。例如父线程需要检查子线程执行完毕等。
我们可以使用一个共享变量,让主线程自旋检查是否完成,如果子线程执行完成,则继续:
|
|
这种方案虽然可以满足一定条件后继续执行,但效率很低下,因为自旋检查会浪费 CPU 时间(占用着 CPU,却什么都不做)。我们期望当条件没有得到满足时,父线程让出 CPU 并休眠等待,直到条件满足后执行。
什么是条件变量
我们可以使用条件变量(condition variable)来等待一个条件变成真。条件变量是一个显式队列,当某些执行状态(即条件)不满足时,线程把自己加入队列,等待该条件。当某个线程改变上述状态时,就唤醒一个或多个等待线程,从而让它们继续执行。
条件变量的使用
|
|
pthread_cond_t:声明条件变量;pthread_cond_wait:在调用时传入一个互斥量,它假定在 wait 调用时,这个互斥量已经上锁。wait 的职责是释放锁,并让调用线程休眠(原子地);pthread_cond_signal:唤醒等待在某个条件变量上的睡眠线程。
具体的使用示例如下:
|
|
在 Go 中使用条件变量需要引入sync包下的Cond变量,具体使用方式如下:
|
|
条件变量的两个坑
虚假唤醒
第一个坑是虚假唤醒。仔细看上面的代码,可以看到对条件变量使用 while(!done){} 循环(Go 中对应 for !done {})而不是if(!done)。原因在于wait()操作在让线程休眠后会释放锁。
- 假设有两个线程 A 和 B,A 由于条件不满足而休眠并释放锁(此时任何其他等待线程可以抢锁);
- 等待一段时间后条件满足,发出信号唤醒线程 A 进入就绪队列;
- 这时假设线程 B 抢先执行,改变了条件变量,线程 B 运行直到结束后;
- 线程 A 开始运行,此时 A 从 wait 返回之前运行,它获取锁,由于是
if判断,所以线程 A 往下执行,但此时条件变量已不满足运行条件,往下运行会出现问题。
所以发信号给线程只是唤醒它们,暗示状态发生了变化,但并不会保证在它运行之前状态一直是期望的情况,即存在虚假唤醒的情况。
为了解决虚假唤醒问题,我们使用while循环而不是if检查条件变量的状态,保证条件变量是满足的状态下再继续执行。
唤醒丢失
第二个坑是唤醒丢失。上面代码中,在判断是否调用wait前先调用lock,这是为了防止线程由于中断导致长眠不醒(即唤醒丢失)。
具体来说,如果父进程调用 thr_join() ,然后检查完 done 的值为 false,试图睡眠。但在调用 wait 进入睡眠之前,父进程被中断。子线程修改变量 done 为 true,发出信号,同样没有等待线程。父线程再次运行时,就会长眠不醒。
wait前先lock可以保证父线程执行完所有wait中的操作并进入等待状态后,子线程才可以调用signal。
信号量(semaphore)
什么是信号量
信号量是(semaphore)用于解决多线程同步问题(例如生产者消费者问题),它是一个同步对象,用于保持在 0 至指定最大值之间的一个计数值。当线程完成一次对该 semaphore 对象的等待(wait)时,该计数值减一;当线程完成一次对 semaphore 对象的释放(release)时,记数值加 1。当计数值为 0,则线程等待该 semaphore 对象不再能成功直至该 semaphore 对象变成 signaled 状态。semaphore 对象的计数值大于 0,为 signaled 状态;计数值等于 0,为 nosignaled 状态。
信号量的初始值决定其行为,所以首先要使用sem_init初始化信号量:
|
|
pshared:为 0 表示信号量是在同一进程的多个线程共享,非 0 则表示信号量在不同进程间共享;value:标识信号量的初始值。
信号量初始化后,我们就可以调用sem_wait(P操作)和sem_post(V操作)与之交互:
sem_wait():信号量的值减 1。当信号量的值大于等于 0 时,立即返回;当信号量的值小于 0 时,让调用线程挂起,直到之后一个sem_post()操作使信号量的值大于等于 0。sem_post():信号量的值加 1,如果有线程等待,唤醒其中一个。
当信号量的值为负数时,这个值就是队列中等待被调用的线程个数。虽然这个值通常不会暴露给使用者。
信号量用作锁
信号量可以用作锁(此时被称为二值信号量),我们可以直接把临界区用sem_wait()/sem_post()包裹。信号量用作锁的关键在于其初始值 x:
|
|
当初始值 x=1 时信号量用作锁,具体分析如下:
- 首先线程 A 调用
sem_wait(),它将信号量的值减为 0。由于只有在值小于 0 时才会等待,所以线程 A 从函数返回并继续执行; - 线程 A 持有锁(即调用
sem_wait()之后,sem_post之前),此时线程 B 尝试进入临界区,调用sem_wait()将信号量减为 -1,然后进入等待执行队列。 - 线程 A 执行完临界区代码后,调用
sem_post(),将信号量增加到 0,唤醒等待线程 B,线程 B 获取锁; - 线程 B 执行结束,调用
sem_post(),信号量恢复为 1。
信号量用作条件变量
信号量也可以用在一个线程暂停执行,等待某一条件成立的场景。看下面的例子,假设一个线程创建另外一线程并且等待它结束:
|
|
当程序运行时,期望看到如下结果:
|
|
从上面代码可知,父线程调用sem_wait(),子线程调用sem_post(),父线程等待子线程执行完成。问题的关键在于信号量初始值X应该是多少?
信号量的初始值应该是 0。考虑以下两种情况:
- 父线程创建了子线程,但子线程并没有运行:这种情况下,父线程调用
sem_wait()会先于子线程调用sem_post()。此时父线程运行,将信号量的值减位 -1,然后休眠等待;子线程运行,调用sem_post(),信号量增加位 0,唤醒父线程,父线程从sem_wait()返回,程序执行完成。 - 子线程在父线程调用
sem_wait()之前就运行结束:这种情况下,子线程会先调用sem_post(),将信号量从 0 增加到 1。当父线程运行时,调用sem_wait(),发现信号量值为 1。于是父线程将信号量从 1 减位 0,无需等待,直接从sem_wait()返回。
所以综上所述,当信号量用作锁时初始值为 1,当信号量用作条件变量时初始值为 0。
信号量的实现
sem_wait和sem_post是硬件原语实现的,所以可以使用上面介绍锁的实现中提到的硬件原语实现,这里以比较并交换原语(CAS)为例,实现逻辑如下:
|
|
Go 中的计数信号量
Go 中的信号量通过导入 sync 包的 WaitGroup 来初始化,具体使用方式如下:
|
|
读者写者锁
前面讲到的锁在使用的时候,灵活性不是很好,例如我们对一个并发数据结构有插入和查找操作,如果直接用lock和unlock,会导致我们在插入和查找时都被锁限制。事实上由于插入操作会修改数据结构,所以需要加锁,而查找操作只是读取该数据结构,并发执行并不会影响读取结果。读者写者锁(reader-writer lock)就是用来完成这种操作的。
读写锁可以是读加锁,写加锁以及未加锁三种状态。每次只能由一个线程处于写加锁状态但是可以有多个线程处于读加锁状态。读写锁是一把锁,它就像多路开关一样:
- 锁处于写加锁状态:阻塞试图对这个锁进行读加锁或写加锁的线程;
- 锁处于读加锁状态:阻塞试图对这个锁进行写加锁的线程,不阻塞试图对这个锁进行读加锁的线程。
使用信号量实现读者写者锁的逻辑如下:
|
|
获取读锁,读者首先获取lock,然后增加reader的数量,追踪目前有多少个读者在访问该数据结构。当第一个读者获取该锁时,读者也会获取写锁,即writelock信号量上调用sem_wait(),最后调用sem_post()释放lock。一旦一个读者获取了读锁,其他读者也会获取这个读锁。但是,想要获取写锁的线程,必须等到所有读者都结束。最后一个退出的写者在“writelock”信号量上调用sem_post(),从而让等待的写者能够获取该锁。
总结
以上就是关于并发编程中锁、条件变量和信号量的相关介绍。再回顾一下:
- 锁本质上是一个变量,我们通过使用
lock()和unlock(),保证仅有一个线程可以访问临界区。锁通过硬件指令实现,硬件指令有:控制中断、测试并设置(TSL)、比较并交换(CAS)、链接的加载和条件式存储(LL/SC)、获取并增加(FAA)。在 Go 中锁是通过 CAS 实现的。 - 条件变量(condition)用于等待一个条件变量变成真时再执行。通过调用
wait休眠等待,调用signal通知条件变量状态改变,唤醒休眠线程。 - 信号量( semaphore)用于解决多进(线)程同步问题,信号量的初始值决定其行为,当初始值为 1 时称为二进制信号量,功能与锁相同;当初始值为 0 时可以用作条件变量。
- 读者写者锁实现了有读有写的情况下并发读,互斥写,从而提升整体性能。