AIGC:内容创作的新时代

2022 年 11 月底在互联网上出现了一个叫 ChatGPT 的人工智能聊天机器人,紧接着它以火箭般的速度在互联网上传播,从 11 月底发布到月活破亿仅用了两个月的时间,与之相比,TikTok 用了 9 个月,Instagram 用了两年半(30 个月),Facebook 则用了 4 年半(54 个月)。与此同时“图文成片”、“AI 绘画”等功能也在各大平台爆火。人工智能的潜力再次被证明,而这些均在来同一个领域:AIGC。
什么是 AIGC
AIGC 全称是 Artificial Intelligence Generated Content,即人工智能自动生成内容。它指通过人工智能技术生成各种类型的内容,如文章、音乐、图像、视频等。是继专业生成内容(PGC)、用户生产内容(UGC)之后的全新的内容生产方式,它可以在创意、表现力、传播、个性化等方面充分发挥技术优势,打造新的数字内容生态和交互形态。
AIGC 工具可以分为三大类:
- 生成:从海量的数据中学习抽象概念,然后通过 概念的组合 生成全新的内容。
- 分类:对内容的分析、特征提取等。
- 转换:包含语言翻译、内容调整、更改标题等。
AI 是如何生成内容的
AIGC 的基本原理是通过模拟人类创造内容的过程,使用大量的数据和计算资源训练模型,并利用这些模型来生成数字内容。
机器学习基础
ChatGPT 的模型 GPT 是一个大型语言模型(LLM),它属于生成式机器学习模型家族。生成式 AI 模型用一句话解释就是:它是一种可以将接受结构化符号集合的输入,并给出相应结构化符号集合的输出的一种函数。即 $y=f(x)$ 。
结构化符号集合包括:
- 单词中的字母
- 句子中的单词
- 图片中的像素
- 视频中的帧
集合间的关系
在了解关系之前,我们需要先区分两个概念,确定性与随机性:
- 确定性:是指在给定特定输入的情况下,总是会产生相同输出的过程。
- 随机性:是指在给定特定输入的情况下,更有可能产生某些输出而不太可能产生其他输出的过程,下面这张概率分布图展示了这种情况。
下面我们来聊一下什么是关系。符号集可以通过不同的方式关联,关系越抽象和微妙,我们就越需要更多的技术来找到这种关系。
- 如果我们将符号序列 [1, 2, 3, 4] 和 [2, 4, 6, 8] 关联,我们可以很容易的看到它们之间的关系符合 $y = 2x$
- 如果我们将 猫 和 狗 联系起来,则它们之间在多个抽象层面有多个关联:
- 作为符号,它们都是字
- 作为字,它们都指动物
- 作为动物,它们都指哺乳动物
- 作为哺乳动物,它们都是宠物 等
- 如果我们将 猫是黑的 和 猫是白的 联系起来,则它们需要更多的概念关联:
- 所有与猫相关的概念都在起作用,例如动物、宠物等
- 所有“黑”与“白”的概念也会相关联
- 如果我们再添加一层 猫是成熟的 和 猫是不成熟的 ,则它们的关联更加复杂:
- 这里的 不成熟 可能是身体的不成熟,但是如果这里用来形容人,则也可能和心理上有关。
- 再添加一层 白色猫是成熟的 和 黑色猫是不成熟的,则整个关联就会变得非常抽象和复杂。
在以上例子中,从 1 到 5 的符号集之间的关系数量越来越多,关系本身也越来越抽象和复杂。当符号集合之间的关系简单且确定时(例如第一个例子),我们不需要太多的存储和计算来将二者关联。但是当符号集之间关系变得复杂且随机时,为了将它们关联,我们需要的大量的计算和存储能力。
概率分布
下面是一张 双缝实验 的图,可以看到光在通过缝隙后,呈现出明暗相间的条纹,这里的亮条纹就是光子落点比较集中的位置,暗条纹就是光子不那么集中的地方。这意味在亮条纹处遇到光子的概率要比暗条纹处遇到光子的概率大很多。
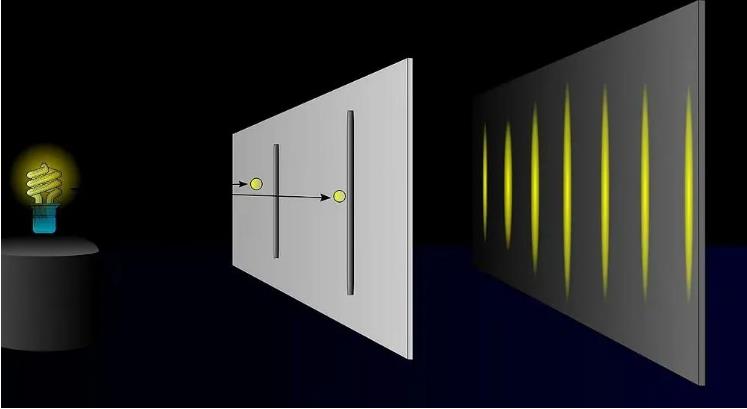
基于以上基础,我们开始尝试理解 AI 是如何生成内容的。
每一次给 AI 的输入实际上是一次搜索查询

上面是分别使用 ChatGPT 和 Midjourney 生成文字和图案片的效果。
当我们输入提示(prompt)时,它会给我相应的回复。我们可能会想这个提示像是一个命令,让 AI 帮我们做某些事情。但其实并非如此,事实上它更像是根据提示的一次搜索,就像我们平时通过搜索引擎搜索内容一样。我们发送搜索词给模型,模型会做如下事情:
- 转换:将我们输入的查询转换为所有可能的数字文件上的坐标,这些是它之前训练过程中见过的;
- 返回:将相应最接近的坐标返回给我们。机器通过不断训练后,它返回的坐标 非常接近 答案。
所以当我们向 AI 发送提示,其实是给它提供了一个方向,告诉它在它的输出空间中寻找你要求它“生成”的内容。
我们在搜索过程中通常会通过不断搜索来缩小结果范围,最终找到我们理想中的答案。同样的,对 AI 来说也是这样:
- 给它一个搜索提示;
- 评估结果;
- 再次查询,回到步骤 1。
就像搜索引擎在它的服务器中拥有爬取的互联网上的内容一样,AI 在它内部的“记忆”中也有经过训练后的结构化的文本。
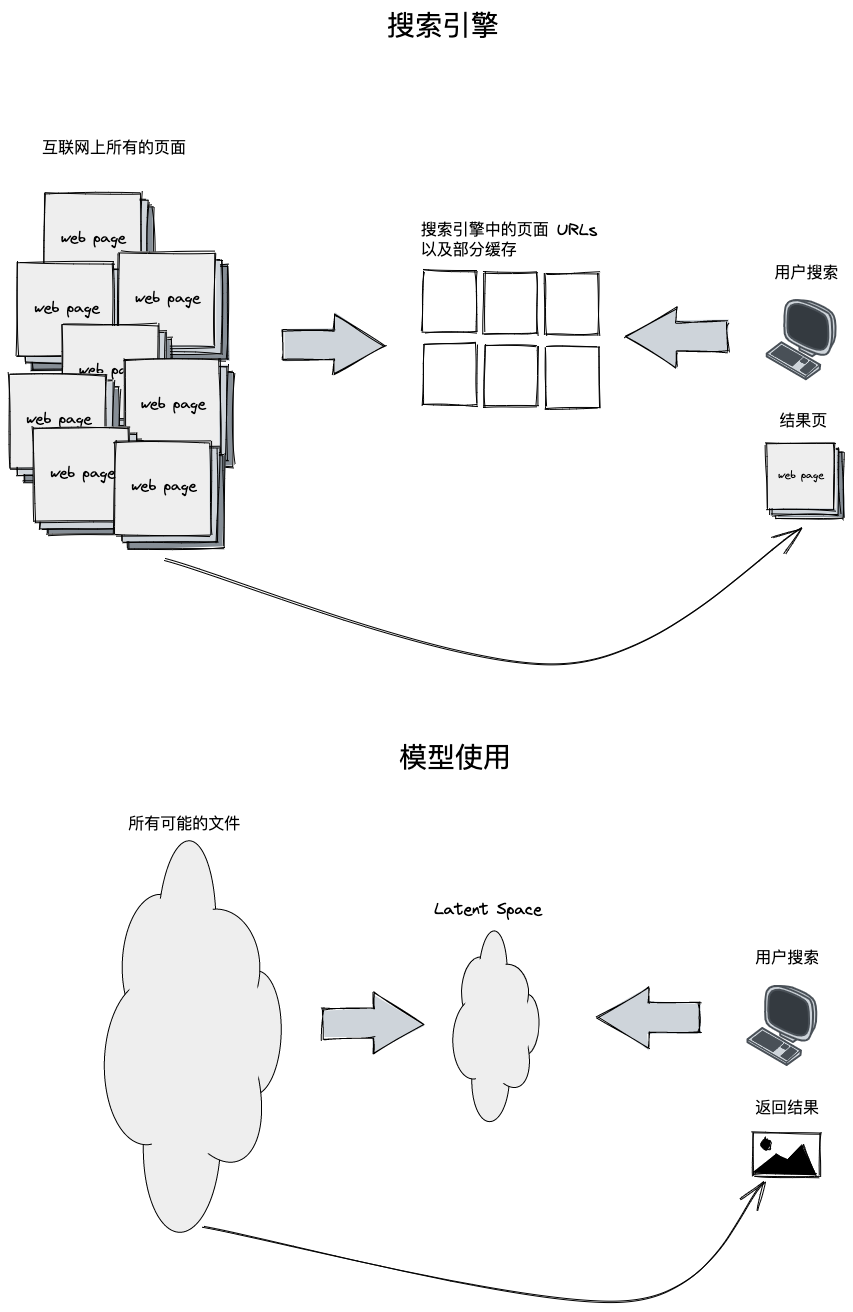
现在我们可以建立搜素引擎和 AI 内容生成的一个概念映射:
| 搜索引擎 | AI 内容生成 |
|---|---|
| 抓取 | 训练 |
| 搜索 | 提示 |
| 优化搜索 | 优化提示 |
| 过滤搜索 | 在模型上设置参数 |
所以当我们使用 AI 生成内容时,最好将提示(prompts)视为一种搜索语句。
Latent Space 上面图中提到 Latent Space 的概念,类比到搜索引擎就是存储 URL 和页面缓存的搜索服务器,那么什么是 Latent Space ? Latent Space 是 压缩数据的一种表示。它的作用是为了找到模式而学习特征并且简化数据的表示。数据压缩的目的是学习数据中较为重要的信息。这种压缩后的状态就是数据的 Latent Space 表示。
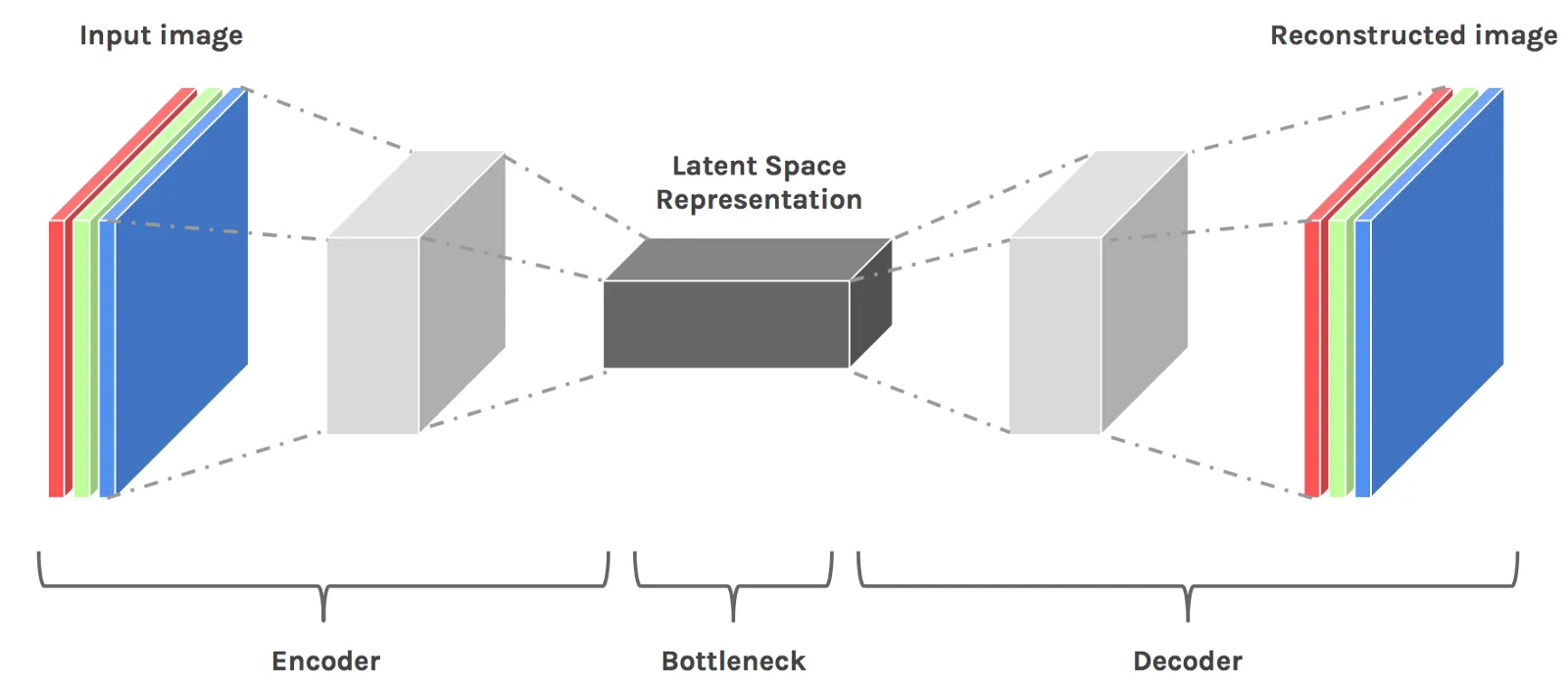
基于 Latent Space 生成结果
将我们在硬盘中的每个文件想象成是三个整数组成的坐标系,代表着三维空间的某个点,就像下面这样:
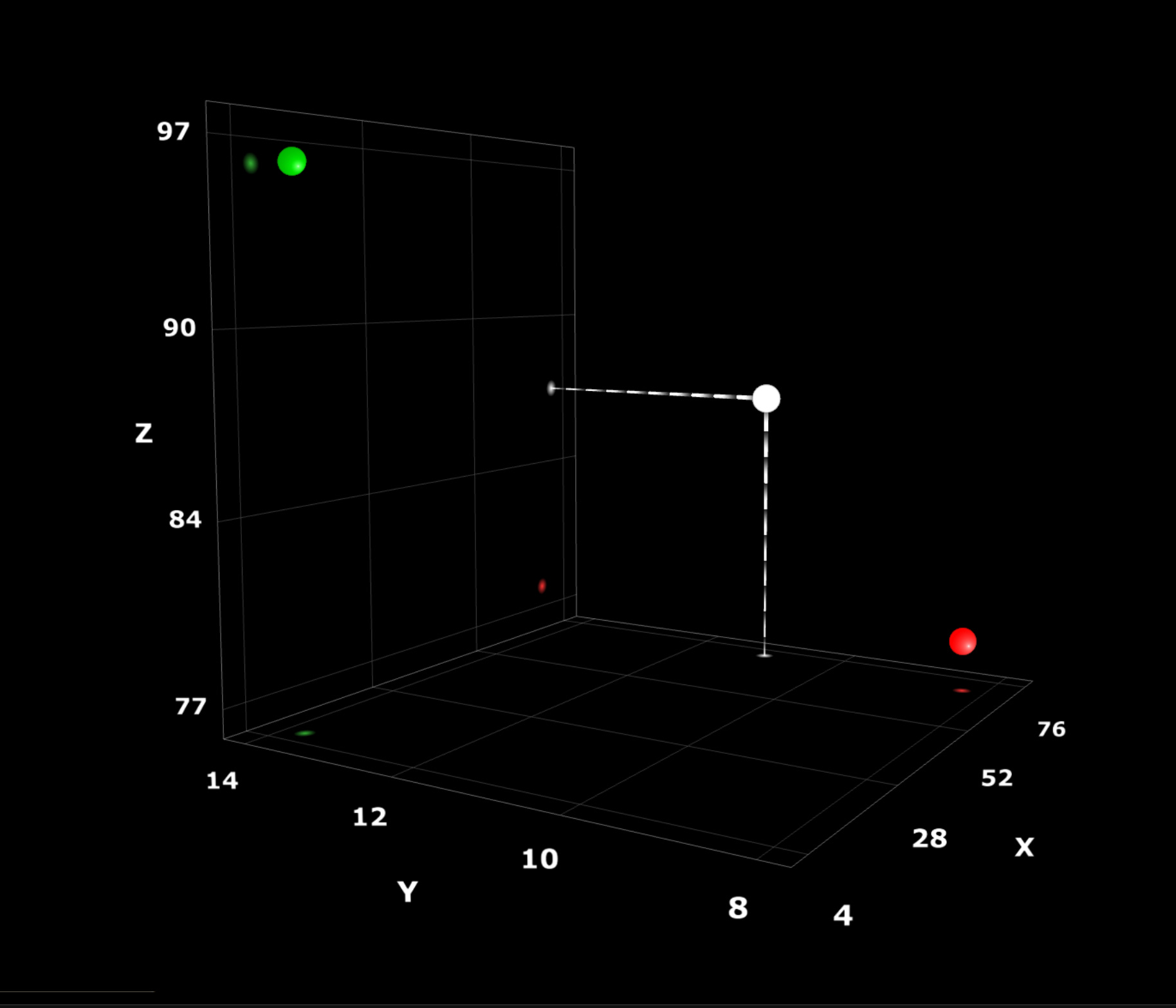
假设一个文件是一张汽车的图片。我们想办法将其转换为一个三维空间中的点,并在三维空间坐标系中绘制。为此我们需要确定图片的哪些特征形成我们的 x、y、z 轴:
- 图片的尺寸和颜色:我们可以将图片的高度作为 x 轴,图片的宽度为 y 轴,所有像素的平均颜色作为 z 轴。
- 抽象概念:我们也可以将“汽车”、“马车”、“自行车” 作为 x、y、z 轴。然后计算图片与这三个概念的接近程度,并将其绘制在三维坐标系中。例如一张摩托车的图片可能位于“汽车”和“自行车”之间。
总之,我们会从图片上选择三个对我们来说最重要的特征,然后将图片转换为三维空间中的某个点。基于以上方法,我们将 10 张与车相关的图片在三维空间表示出来:

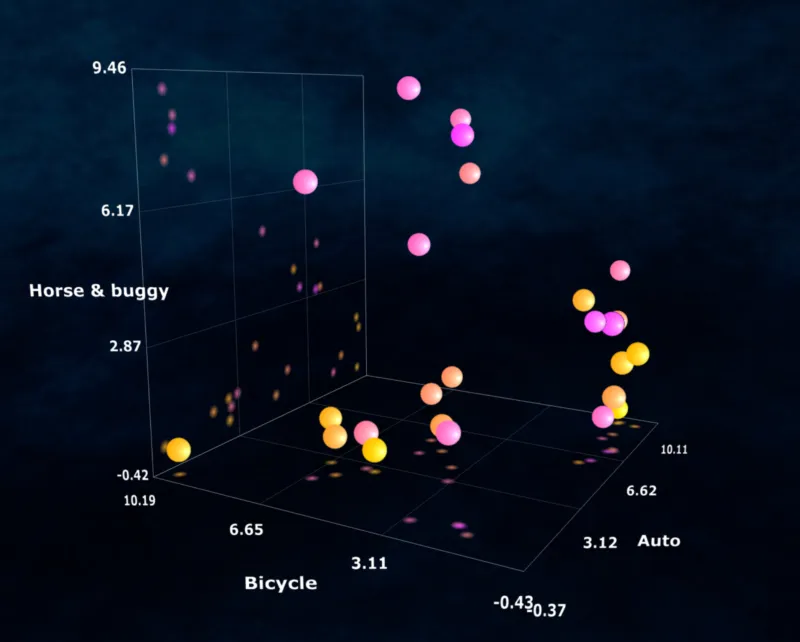
通过上面这些点在三维空间的分布,我们可以在不看原始数据的情况下推断出这 10 张图片的整体情况(整个数据集的有用信息)。
深度学习模型的内部“记忆”就是由类似于上面这个简单结构的多维版本组成。我们上面提到图片生成模型 Midjourney 就涉及向模型展示海量的图片,让它从图片中提取不同的特征和质量(例如“汽车”、“自行车”和“马车”),然后将表示图像的聚类簇压缩在这个多维空间中,使其不同区域倾向于对应相似类型的图像。
聚类和聚类簇 聚类是最常见的无监督学习任务,通过给机器输入样例来检测潜在的有价值聚类簇。
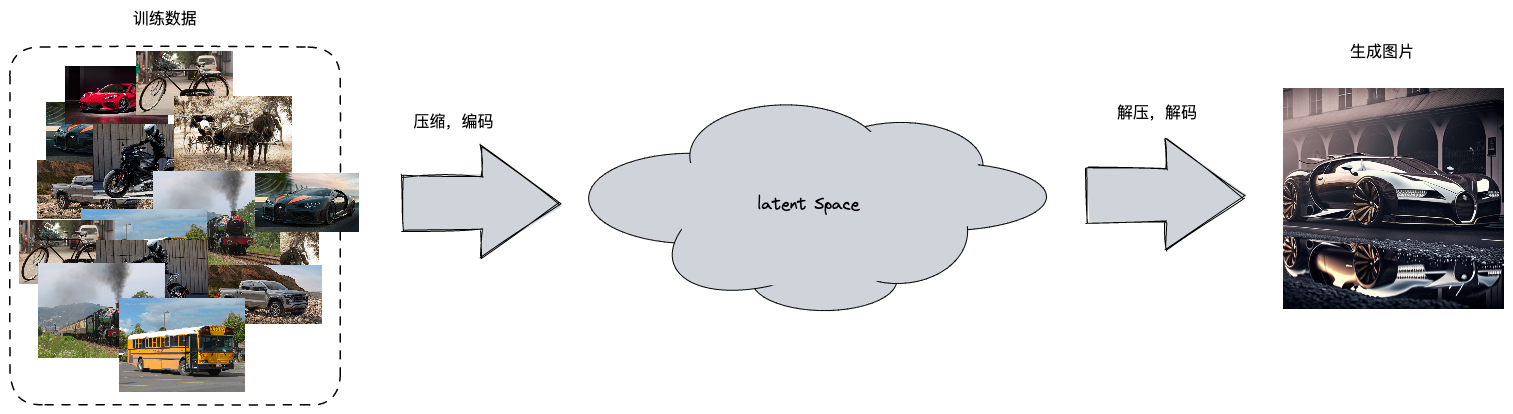
完成训练的模型是一个高度压缩的数字表示,它代表了机器在训练期间从数据集中提取出来的概念和特征的多维空间(即 Latent Space )。在这个空间中,类似的事物会聚集在一起,而不同的事物则分散开来。
关于 AI 的两个事实
AI 并不知道事实也不会提供任何意见
可以想象,对 ChatGPT 来说,从生成毫无意义的词到连贯的句子,每个符号都是概率分布中的一个点。当我们向 ChatGPT 输入 “我很开心” 并点击提交按钮后,它给到我们的结果可以看作是使用函数计算并得出符号集合的结果。看起来似乎模型真的能理解 “开心” 的含义,但实际上在所有由模型产生的符号集合组成的空间(该空间包含从无意义的词和句子到各种现实情况)一些区域包含了人类能够理解的“开心” 的符号集合,并且在临近的区域包含了人类能理解的其他情绪相关的词,例如“悲伤”,“愤怒”等。这个空间经过大量的训练后才被塑造成了特定的 “形状”。
当我们和 ChatGPT 讨论一些与事实相关的话题,例如“大熊猫的现状以及它是否濒临灭绝”时,不要觉得我们是在请教一个学者告诉我们事实。相反,我们应该把这种操作看成是这样:通过给模型输入提示来观察概率分布中对应于“大熊猫”的一组事实和概念集群,所以如果有另一个人也在输入这个问题,则我们可能得到相反的答案,这是因为我们得到了概率分布中不同的区域并在其中找到了不同的点。这时候我们说 AI 出现了 “幻觉(Hallucination)”,就像下面这样:

这时就需要修正模型的概率分布。我们可以通过以下手段,塑造模型的概率分布:
- 训练:通过高质量数据训练一个基础模型;
- 微调:对基础模型进行探索并发现在可能输出的空间中存在有问题的区域,我们使用更加精细的训练数据来微调,从而扩大或缩小某些区域;
- 基于人类反馈的强化学习(RLHF):引入真人反馈来调整概率空间的形状,使其能够尽可能紧密地覆盖所有可能的输出空间中与真实世界相对应的点。如果能够成功实现这一点,那么我们对模型概率空间所做出的所有观察都将似乎是正确的。
这就是为什么 ChatGPT 在给出答案后,都会有一个 👍 和 👎 的选项。
AI 并不了解我们
当我们在和 ChatGPT 对话的时候,随着我们对话的深入,似乎它变的越来越了解你,就好像是从陌生人逐渐成为朋友,但事实上并不是这样。这里就涉及到 token window 的概念。
[!faq] ML 中的 token window 是什么?(from Google Bard) 在机器学习中,“token window"是指一个固定大小的滑动窗口,用于从标记序列中提取特征。该窗口通常用于计算窗口内标记的频率或其他统计信息。token window是自然语言处理中常用的技术,因为它可以用于识别单词、短语和其他有意义的文本单位。
例如,一个大小为 3 的token window可以用于从句子"I like dogs.“中提取特征。该窗口将以句子中的每个标记为中心,并且特征将是窗口内每个标记的频率。然后可以使用这些特征来训练机器学习模型,将句子分类为不同的类别,例如"positive"或"negative”。
token window是从标记序列中提取特征的强大工具。然而,需要注意的是,窗口大小会影响结果的准确性。较大的窗口将捕捉更多信息,但也可能更嘈杂。较小的窗口将捕捉更少的信息,但可能更准确。
ChatGPT 之前的语言模型如何工作?
说起语言模型我们并不陌生,像小米的小爱同学、百度的小度等都是人工智能,但是相比于 ChatGPT,它们有一个显著的特征:无法连续和它聊天。
使用普通的语言模型,我们给模型一组输入,它给我们一个输出。我们的输入就是输入到模型的 token window 中。
- token:就是上面提到的符号,它在 ML 中的术语是 token。
- window:模型可以识别并转化的 token 数量(就像是 token 的池子)。
当我们使用之前的语言模型时,我们将 token 放入 token window 中,然后模型返回 Latent Space 中对应的点。

这里涉及到非常关键的一点:概率空间不会因为我放入 token window 中的 token 而发生变化。模型的权重在我从一个 token 到另一个 token 时保持不变。它不会记得之前 token window 中的内容。
ChatGPT 的不同之处
ChatGPT 是一个具有单一、大型 token window 的 LLM,但它使用 token window 的方式使得我们与机器对话更像是与真人对话。


可以看到,在上面和 ChatGPT 的对话中,它根据我们第一次对话中给它的上下文,在第二次和第三次的对话中成功的表演一个角色。
ChatGPT 通过 token window 来管理它的“记忆”,对话的上下文会随着每次对话回合的新输入的内容而不断更新。每当处理一个新的输入时,最老的输入会被从“记忆”中移除,从而实现聊天机器人能够专注于最近的上下文的表象。
但这种“记忆”是短期的,如果我们重新开一个新的对话窗口,则我们之前提到的上下文就不复存在。
基于以上,我们就理解了为什么 GPT-4 的 32k token window 非常重要(相比之下,GPT-3.5 是 4k),因为这代表它可以记住更多的上下文,从而使回答更加准确。
AIGC 的现状
随着 OpenAI 开放 API,基于 GPT 的人工智能应用开始在 GitHub 上爆发,详细列表可以查看:awesome-chatgpt-api。与此同时,大厂们也纷纷跟进,抢着发布自己的大模型。
Microsoft
Microsoft 作为 OpenAI 大股东(持有 OpenAI 49% 的股份), 直接 all in AI:
连续发布了基于 GPT-4 的 New bing Chatbot、以文生图、Microsoft 365 Copilot 以及 Github Copilot X:
- Microsoft 365 Copilot(由 GPT-4 驱动),旨在协助用户生成文档、电子邮件、演示文稿等。 https://youtu.be/S7xTBa93TX8
- Github 发布的 Copilot X(由 GPT-4 驱动),旨在为每个团队、项目和代码库提供个性化的开发体验,让开发者更高效地开发软件,提高工作满意度。 https://youtu.be/4RfD5JiXt3A
Google 发布了自己的聊天机器人 Bard:https://bard.google.com/,目前可以申请加入白名单,但是仅限美国和英国 IP,且仅支持英语。 同时 Google 也为自己的办公软件带来了 AI,帮助用户在包括 Google Documents、Google Sheets 和 Gmail 中生成内容。 A new era for AI and Google Workspace - YouTube
Adobe
Adobe 发布的 Firefly,支持通过文字生成图像/矢量图/3D 模型。 https://youtu.be/_sJfNfMAQHw
百度
百度在前段时间发布了自己的聊天机器人“文心一言”,目前可以申请加入体验:文心一言。
写在最后
AI 时代已经来临,它对我们的影响到底有多大,也许还无法确定,但是我相信 AI 对人类社会的巨大影响将注定远超蒸汽机。
瓦特 1776 年推出可商用的蒸汽机,到 1804 年英国首次出现蒸汽机推动的火车,间隔 28 年。按照沃顿商学院教授 Ethan Mollick 的说法,十九世纪初美国的各类小工厂采用蒸汽机后,效率普遍提高 25%,而 ChatGPT 之类的工具推出后,很多需要高技能的行业人员 (从程序员到律师,到游戏设计等等) 反映使用此工具对效率的提高从 30%到 80% 不等。这还只是序曲,这个工具本身还在加速变得更好。各行各业的效率的提高还会不断组合叠加。
1776 年的美国人根本无法想象和理解,将近一百年后铁路贯通美洲大陆对经济模式和社会结构的革命性影响。 2023 年的人们,还无法预测相对于蒸汽机催生出的铁路系统, AI 会创造出什么新的系统来。但可以肯定的是,它的影响会远超蒸汽机带来的工业革命,而且投入实用的速度将极快,我们无需等待 28 年看到 AI 时代的“火车”浮现。
参考
- Towards artificial general intelligence
- A Deep Dive into NLP Tokenization and Encoding with Word and Sentence Embeddings
- What Is Stable Diffusion and How Does It Work?
- Building a Multi-Turn Chatbot with GPT and SageMaker: A Step-by-Step Guide
- 王川:关于 chatGPT 的随想
- 人工智能时代已经开始 | 盖茨笔记
- 为什么深度学习和神经网络需要GPU?
- Google Workspace AI 来了! | TechBriefly CN
- 细数微软和OpenAI的前世今生_投资界 (pedaily.cn)